
Semana 16 - Datos Semi-estructurados

Es viernes y ¡qué día tan maravilloso para ejercitar los músculos del análisis JSON!
A continuación tenemos el script de configuración:
create or replace file format json_fftype = jsonstrip_outer_array = TRUE;create or replace stage week_16_frosty_stageurl = 's3://frostyfridaychallenges/challenge_16/'file_format = json_ff;create or replace table <schema>.week16 asselect t.$1:word::text word, t.$1:url::text url, t.$1:definition::variant definition from @week_16_frosty_stage (file_format => 'json_ff', pattern=>'.*week16.*') t;
Resultado final
select *from (<your query goes here>) subwhere word like 'l%';
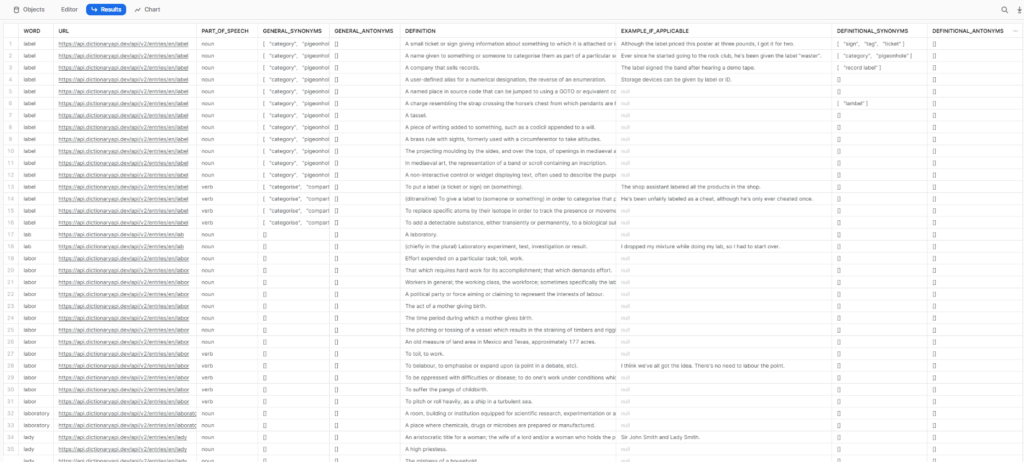
Si es correcto, entonces (sin el filtro "where word like 'l%'") :
- count(word) debería obtener 32.295 filas
- count(distinct word) debería obtener 3.000 filas
Fuentes de datos
- https://www.ef.co.uk/english-resources/english-vocabulary/top-3000-words/
- https://dictionaryapi.dev/
PUNTOS EXTRA:
Si tienes la suerte de estar en una de las siguientes regions, intenta aplicar la optimización de búsqueda en tu tabla utilizando una ruta variante.
Recuerda que si deseas participar:
- Regístrate como miembro de Frosty Friday. Puedes hacerlo haciendo clic en la barra lateral y luego yendo a "REGISTRARSE" (ten en cuenta que unirte a nuestra lista de correo no te proporcionará una cuenta de Frosty Friday).
- Publica tu código en GitHub y asegúrate de que sea de acceso público (consulta nuestra guía si no sabes cómo hacerlo).
- Publica la URL en los comentarios del desafío.
Si tienes alguna pregunta técnica que te gustaría plantear a la comunidad, puedes hacerlo aquí, en nuestro hilo dedicado a estos retos.